katana 介绍
katana 是一款强大的新一代的网络爬虫工具,通过使用 katana,用户能够快速的进行互联网资源的爬取和渗透测试阶段的收集任务。
特点
katana 有以下特点:
- 快速及高可配置的网络爬虫
- 标准及无头模式
- 主动和被动模式
- JavaScript 脚本爬取解析
- 定制的表单内容自动填充
- 爬取范围控制
- 可自定义设置输出字段
- 输入数据 支持标准输入 (STDIN),URL 和列表 (LIST)
- 输出数据 支持 STDOUT、文件和 JSON 格式
安装
接下来介绍如何安装 katana
katana 的安装需要 go1.18 版本以上,可以执行以下命令或下载 Github 仓库的发布版本。
go install github.com/projectdiscovery/katana/cmd/katana@latest
windows 在安装中可能会遇到以下报错:
github.com/smacker/go-tree-sitter/javascript: build constraints exclude all Go files in C:\Users\overstarry\go\pkg\mod\github.com\smacker\[email protected]\javascript
# github.com/smacker/go-tree-sitter
go\pkg\mod\github.com\smacker\[email protected]\iter.go:17:18: undefined: Node
go\pkg\mod\github.com\smacker\[email protected]\iter.go:21:21: undefined: Node
go\pkg\mod\github.com\smacker\[email protected]\iter.go:25:20: undefined: Node
go\pkg\mod\github.com\smacker\[email protected]\iter.go:30:26: undefined: Node
go\pkg\mod\github.com\smacker\[email protected]\iter.go:34:20: undefined: Node
go\pkg\mod\github.com\smacker\[email protected]\iter.go:38:32: undefined: Node
go\pkg\mod\github.com\smacker\[email protected]\iter.go:43:9: undefined: Node
go\pkg\mod\github.com\smacker\[email protected]\iter.go:46:18: undefined: Node
go\pkg\mod\github.com\smacker\[email protected]\iter.go:68:40: undefined: Node
可以使用以下命令解决:
choco install zig
set CGO_ENABLED=1&set GOOS=windows&set GOARCH=amd64&set CC=zig cc&set CXX=zig c++
go install github.com/projectdiscovery/katana/cmd/katana@latest
Docker 安装
katana 还支持 Docker 进行使用,执行以下命令:
docker pull projectdiscovery/katana:latest
docker run projectdiscovery/katana:latest -u https://tesla.com
使用
接下来的使用环境会以 Docker 环境为主。
爬取多个 url
使用 -u 参数,可以爬取指定网站的数据,可以看到 overstarry.vip 的网站链接都显示了。
docker run projectdiscovery/katana:latest -u https://overstarry.vip
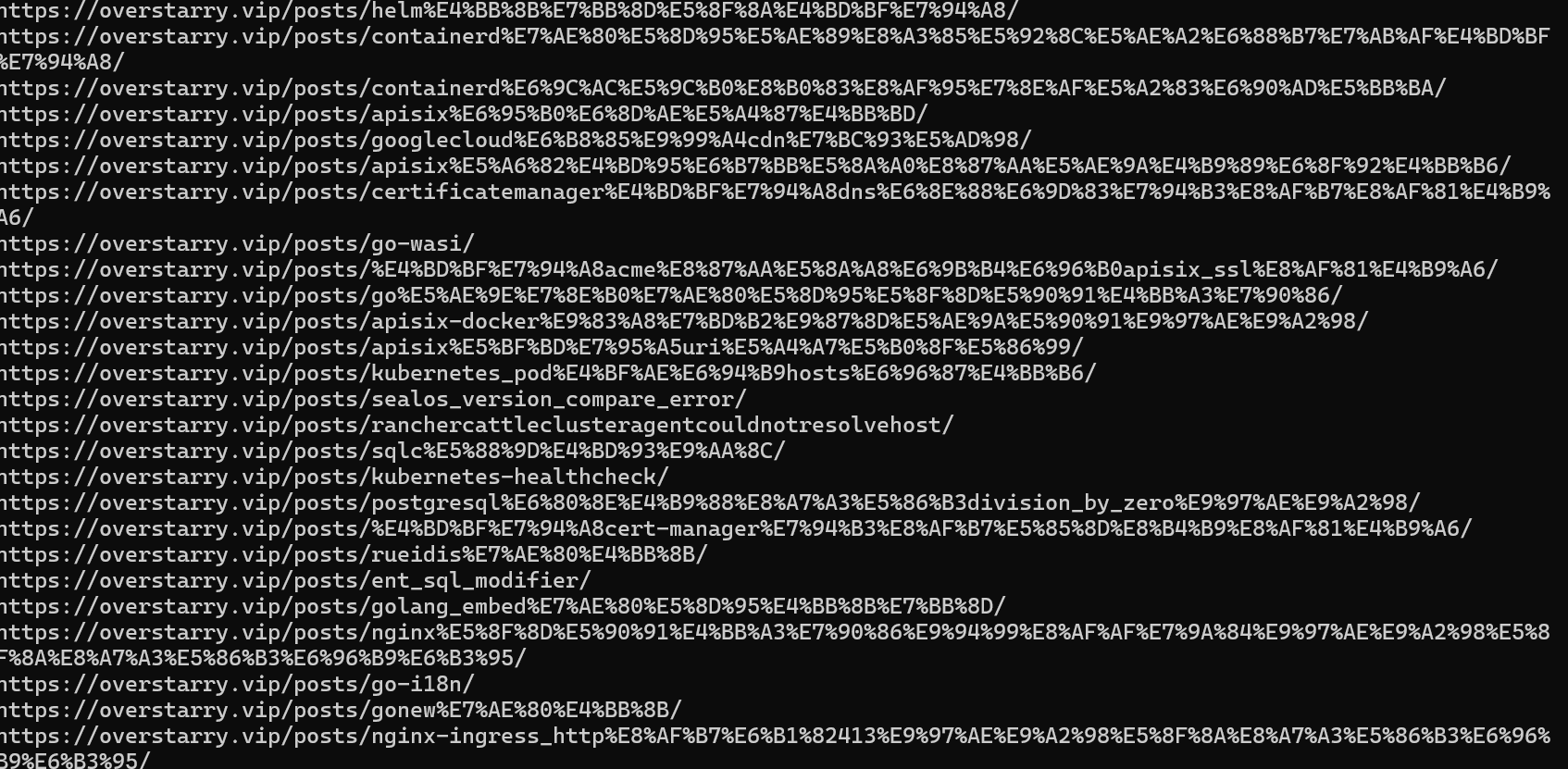
如果想要一次获取多个网站的数据,直接添加多个 URL 即可,多个 URL 之间以逗号分隔。
需要注意的是,爬取 url 时,会将当前 url 上的所有链接都会获取下来,包括超链接。
爬取模式
1 标准
标准模式使用 go 原生 http 进行数据采集,采集速度会更快,但不会处理 Javascript 和 Dom 渲染,不适合用于一些有复杂动态渲染的网站,
2 无头浏览器模式
无头模式使用无头浏览器,在浏览器上下文进行数据的获取,有以下优点:
- Http 指纹合法
- 可以处理更复杂的一些网站
爬取范围
如果没有限定爬取范围,katana 爬取可能会是无止境的,所有一般需要限定爬取的数据范围。
-field-scope
有三个选项:
* rdn 爬取根域名及所有子域名 (默认)
* fqdn 限定爬取的子域名
* dn 爬取的范围为指定关键字域名
-crawl-scope
-crawl-out-scope
定义不爬取的内容范围,支持正则表达式
其它
除了这些参数,katana 还支持很多其它参数,感兴趣的读者可以自行研究
katana 库
除了 cli 使用外,katana 还支持在代码中进行使用。